Инструменты · SEO Bundle
Сбор семантики через Serpstat
Подтягиваем ключи, частотность и конкурентов из Serpstat по API прямо в сводную таблицу — вся семантика в одном окне.
Скачать программу
Windows, macOS, Linux · v0.2.0
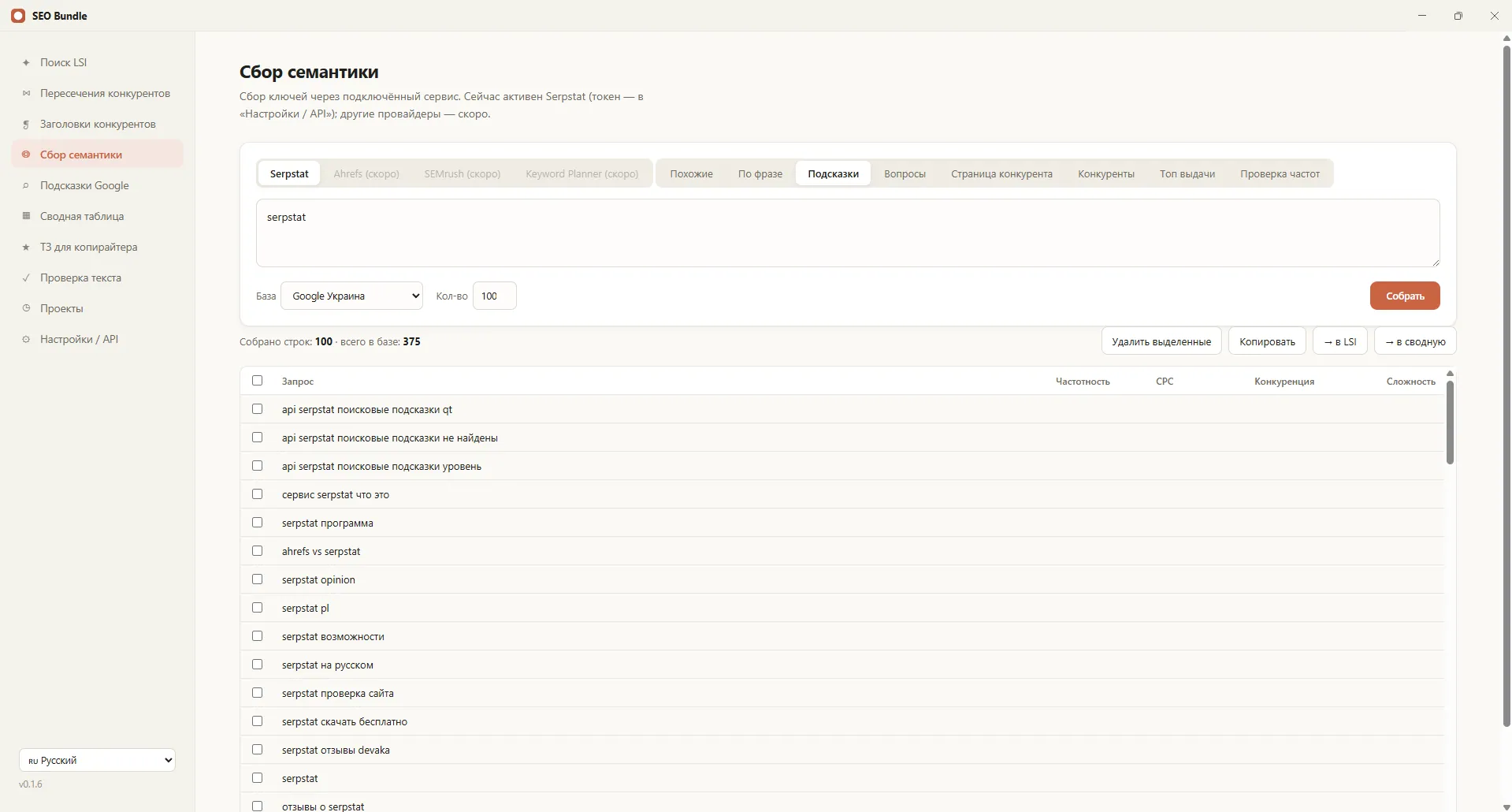
Сбор семантики через Serpstat — это получение ключей, частотности и конкурентов прямо из базы Serpstat по API. В программе SEO Bundle это встроено: вы вводите токен и запрос, а программа подтягивает связанные ключи, подсказки, запросы конкурентов и топ выдачи в одну сводную таблицу. Вся семантика собирается в одном окне, без ручного копирования из веб-интерфейса.
Что даёт Serpstat
Serpstat — одна из сильнейших баз по ключам и частотности для рынков Украины и СНГ. Через неё видно реальный спрос: сколько раз ищут запрос, какие связанные фразы есть и кто из конкурентов ранжируется. Это фундамент для семантического ядра.
SEO Bundle обращается к Serpstat по API, поэтому ключевые слова Serpstat попадают сразу в рабочую таблицу программы, а не остаются в отдельном сервисе. Это убирает рутину переноса данных между инструментами.
Как программа собирает семантику
Парсинг Serpstat в SEO Bundle использует несколько методов базы и сводит результат вместе.
- Связанные запросы по вашему ключу;
- Все запросы, содержащие фразу;
- Живые поисковые подсказки;
- Ключи, по которым ранжируется страница конкурента;
- Топ выдачи и вопросные запросы для FAQ.
Каждый источник тегируется, поэтому видно, откуда пришёл запрос, и легко отфильтровать лишнее.
Что попадает в сводную таблицу
Все собранные данные складываются в единую таблицу с частотностью и группировкой. С ней удобно работать: фильтровать, чистить, переносить фразы между группами и формировать ядро.
- Запросы с частотностью из Serpstat;
- Источник каждого запроса (related, подсказки, конкуренты);
- Группировка и фильтры по столбцам;
- Готовность к кластеризации и передаче в ТЗ.
Зачем собирать всё через один токен
Один токен Serpstat закрывает основной сбор данных: и частотность, и конкурентов, и связанные запросы. Это дешевле и проще, чем держать несколько подписок, а лимиты расходуются прозрачно. Семантическое ядро Serpstat собирается за один проход, без переключения между сервисами.
Дополнительно программа использует бесплатные подсказки Google, поэтому часть данных собирается вообще без расхода лимитов.
Откуда берутся цифры частотности
База хранит, сколько раз ищут запрос в выбранном регионе. Эти цифры показывают реальный спрос: что популярно, а что почти не ищут. Без частотности ядро превращается в список без приоритетов, по которому непонятно, с чего начинать.
Программа подтягивает частотность сразу к каждому запросу, поэтому ключи можно ранжировать по важности прямо в таблице.
Разведка конкурентов через базу
Кроме ключей, сервис показывает, по каким запросам ранжируются сайты-соперники. Это помогает увидеть чужой спрос и найти запросы, которые вы упускаете. Данные о соперниках попадают в ту же таблицу и сравниваются с вашими.
Так один источник закрывает и сбор ключей, и разведку рынка, без переключения между сервисами.
Для каких задач подходит
Сбор данных через базу нужен на старте любого проекта и при регулярном расширении ядра. Магазину он даёт семантику каталога, сайту услуг — запросы под услуги и регионы, блогу — темы статей. Везде, где нужен реальный спрос, а не догадки.
Регулярное расширение ядра
Семантика не статична: появляются новые товары, услуги и формулировки. Периодический сбор данных помогает вовремя замечать новый спрос и добавлять под него страницы раньше соперников. Программа хранит проекты, поэтому к ядру удобно возвращаться и дополнять его.
Такой подход превращает разовый сбор в управляемый процесс: ядро растёт вместе с бизнесом, а не устаревает через полгода после запуска.
В составе семантического ядра
Данные Serpstat — основной источник для сбора семантического ядра. Вместе с подсказками и пересечениями конкурентов они формируют полную картину спроса, на основе которой готовится ТЗ для копирайтера. Так сбор ключей сразу переходит в работу над контентом.
Минус-слова и чистка
Сырые данные всегда содержат лишнее: чужие бренды, нерелевантные города, мусорные фразы. Прямо в таблице удобно отфильтровать их и собрать список минус-слов. Чистое ядро экономит бюджет и на органике, и на будущей контекстной рекламе.
Фильтры по столбцам и группировка помогают быстро отделить целевые ключи от шума, не выгружая данные в сторонние таблицы.
Чем удобнее веб-интерфейса
В веб-версии Serpstat данные приходится выгружать по частям и сводить вручную. Программа делает это автоматически: несколько методов в один клик, единая таблица, фильтры и группировка. Вы экономите время и не теряете данные при переносе между сервисами и таблицами, а весь сбор семантики идёт в едином окне программы.
Как начать
Сбор семантики через Serpstat — одна из функций десктоп-программы SEO Bundle. Скачайте приложение на главной странице, добавьте свой токен Serpstat и соберите ядро по первому запросу. По вопросам внедрения в команде напишите нам в Telegram.
Частые вопросы
Нужна ли подписка Serpstat?
Да, для сбора через API нужен токен Serpstat. Часть данных программа собирает бесплатно через подсказки Google, но частотность и конкурентов даёт именно Serpstat.
Какие данные собирает программа?
Связанные запросы, фразы, подсказки, ключи конкурентов, топ выдачи и вопросы. Всё сводится в одну таблицу с частотностью и источником.
Чем это лучше веб-версии Serpstat?
Программа объединяет несколько методов в один проход и собирает данные в единую таблицу с фильтрами. Не нужно выгружать и сводить отчёты вручную.
Расходуются ли лимиты Serpstat?
Да, запросы к API расходуют лимиты вашего тарифа, и расход виден прозрачно. Подсказки Google при этом бесплатны и лимиты не тратят.