Інструмент програми
Збір семантики через Serpstat
Тягнемо ключі, частотність і конкурентів прямо з Serpstat по API в одну зведену таблицю — уся семантика в одному вікні, без ручного копіювання.
Завантажити програму
Windows, macOS, Linux · v0.2.0
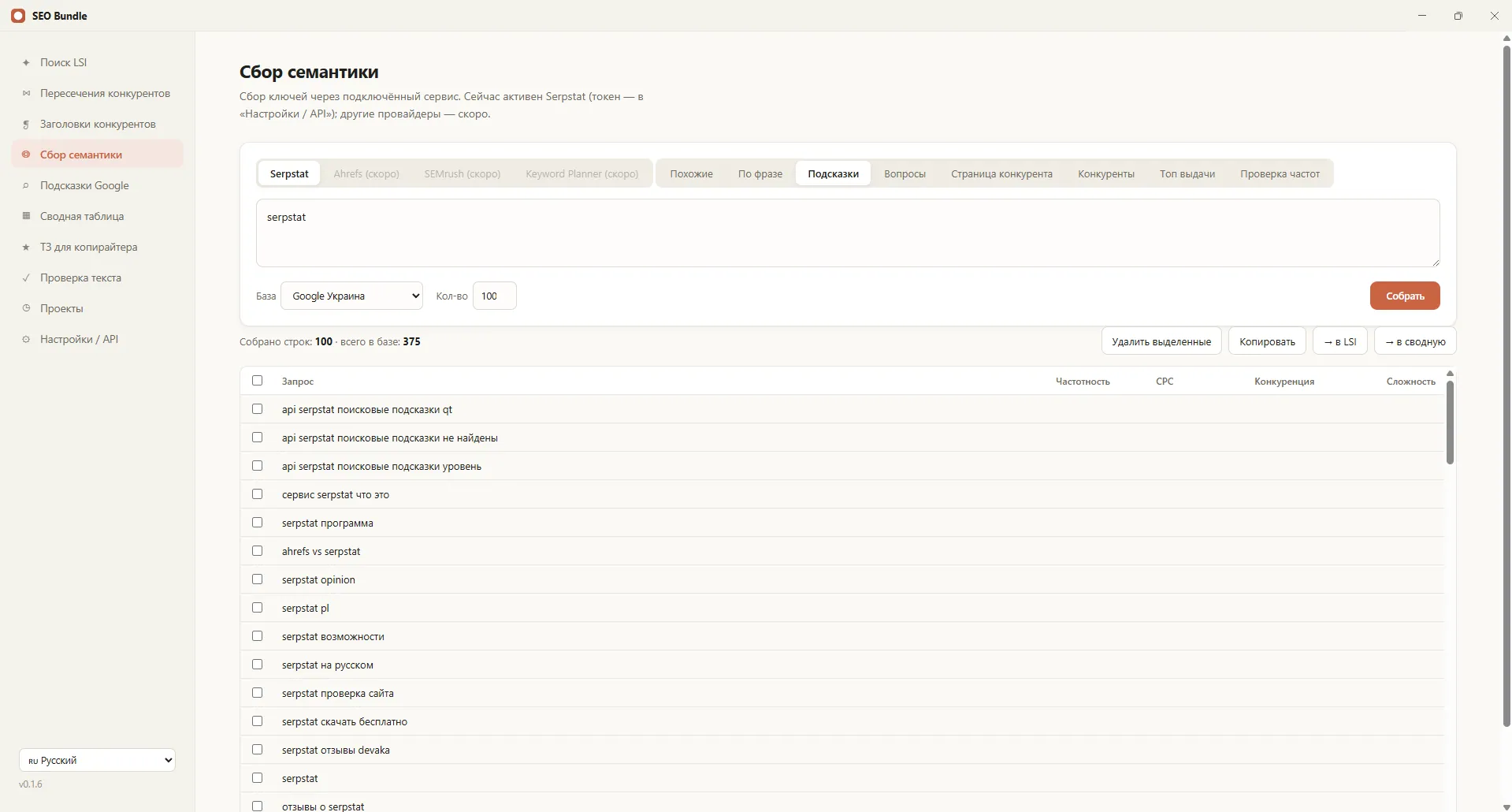
Збір семантики через Serpstat — це отримання ключів, частотності та конкурентів прямо з бази Serpstat по API. У програмі SEO Bundle це вбудовано: ви вводите токен і запит, а програма підтягує пов'язані ключі, підказки, запити конкурентів і топ видачі в одну зведену таблицю. Уся семантика збирається в одному вікні, без ручного копіювання з вебінтерфейсу.
Що дає Serpstat
Serpstat — одна з найсильніших баз за ключами й частотністю для ринків України та СНД. Через неї видно реальний попит: скільки разів шукають запит, які пов'язані фрази є та хто з конкурентів ранжується. Це фундамент для семантичного ядра.
SEO Bundle звертається до Serpstat по API, тому ключові слова Serpstat потрапляють одразу в робочу таблицю програми, а не лишаються в окремому сервісі. Це прибирає рутину перенесення даних між інструментами.
Як програма збирає семантику
Парсинг Serpstat у SEO Bundle використовує кілька методів бази й зводить результат разом.
- Пов'язані запити за вашим ключем;
- Усі запити, що містять фразу;
- Живі пошукові підказки;
- Ключі, за якими ранжується сторінка конкурента;
- Топ видачі та запитальні запити для FAQ.
Кожне джерело тегується, тому видно, звідки прийшов запит, і легко відфільтрувати зайве.
Що потрапляє у зведену таблицю
Усі зібрані дані складаються в єдину таблицю з частотністю та групуванням. З нею зручно працювати: фільтрувати, чистити, переносити фрази між групами й формувати ядро.
- Запити з частотністю із Serpstat;
- Джерело кожного запиту (related, підказки, конкуренти);
- Групування та фільтри за стовпцями;
- Готовність до кластеризації та передачі в ТЗ.
Навіщо збирати все через один токен
Один токен Serpstat закриває основний збір даних: і частотність, і конкурентів, і пов'язані запити. Це дешевше й простіше, ніж тримати кілька підписок, а ліміти витрачаються прозоро. Семантичне ядро збирається за один прохід, без перемикання між сервісами.
Додатково програма використовує безкоштовні підказки Google, тому частина даних збирається взагалі без витрати лімітів.
Звідки беруться цифри частотності
База зберігає, скільки разів шукають запит у вибраному регіоні. Ці цифри показують реальний попит: що популярне, а що майже не шукають. Без частотності ядро перетворюється на список без пріоритетів, за яким незрозуміло, з чого починати.
Програма підтягує частотність одразу до кожного запиту, тому ключі можна ранжувати за важливістю прямо в таблиці.
Розвідка конкурентів через базу
Крім ключів, сервіс показує, за якими запитами ранжуються сайти-суперники. Це допомагає побачити чужий попит і знайти запити, які ви втрачаєте. Дані про суперників потрапляють у ту саму таблицю й порівнюються з вашими.
Так одне джерело закриває і збір ключів, і розвідку ринку, без перемикання між сервісами.
Для яких задач підходить
Збір даних через базу потрібен на старті будь-якого проєкту й під час регулярного розширення ядра. Магазину він дає семантику каталогу, сайту послуг — запити під послуги та регіони, блогу — теми статей. Усюди, де потрібен реальний попит, а не здогади.
Регулярне розширення ядра
Семантика не статична: з'являються нові товари, послуги й формулювання. Періодичний збір даних допомагає вчасно помічати новий попит і додавати під нього сторінки раніше за суперників. Програма зберігає проєкти, тому до ядра зручно повертатися й доповнювати його.
Такий підхід перетворює разовий збір на керований процес: ядро росте разом із бізнесом, а не застаріває через пів року після запуску.
У складі семантичного ядра
Дані Serpstat — основне джерело для збору семантичного ядра. Разом із підказками та перетинами конкурентів вони формують повну картину попиту, на основі якої готується ТЗ для копірайтера. Так збір ключів одразу переходить у роботу над контентом.
Мінус-слова й чистка
Сирі дані завжди містять зайве: чужі бренди, нерелевантні міста, сміттєві фрази. Прямо в таблиці зручно відфільтрувати їх і зібрати список мінус-слів. Чисте ядро економить бюджет і на органіці, і на майбутній контекстній рекламі.
Фільтри за стовпцями та групування допомагають швидко відділити цільові ключі від шуму, не вивантажуючи дані в сторонні таблиці.
Чим зручніше за вебінтерфейс
У вебверсії Serpstat дані доводиться вивантажувати частинами й зводити вручну. Програма робить це автоматично: кілька методів в один клік, єдина таблиця, фільтри та групування. Ви економите час і не втрачаєте дані під час перенесення між сервісами, а весь збір семантики йде в єдиному вікні програми.
Як почати
Збір семантики через Serpstat — одна з функцій десктоп-програми SEO Bundle. Завантажте застосунок на головній сторінці, додайте свій токен Serpstat і зберіть ядро за першим запитом. Щодо впровадження в команді напишіть нам у Telegram.
Поширені запитання
Чи потрібна підписка Serpstat?
Так, для збору через API потрібен токен Serpstat. Частину даних програма збирає безкоштовно через підказки Google, але частотність і конкурентів дає саме Serpstat за вашим тарифом.
Які дані збирає програма?
Пов'язані запити, фрази, підказки, ключі конкурентів, топ видачі та запитання. Усе зводиться в одну таблицю з частотністю та джерелом кожного запиту для зручної роботи.
Чим це краще за вебверсію Serpstat?
Програма об'єднує кілька методів в один прохід і збирає дані в єдину таблицю з фільтрами. Не потрібно вивантажувати й зводити звіти вручну між кількома вкладками.
Чи витрачаються ліміти Serpstat?
Так, запити до API витрачають ліміти вашого тарифу, і витрата видно прозоро. Підказки Google при цьому безкоштовні й лімітів не витрачають, тож частина збору безплатна.